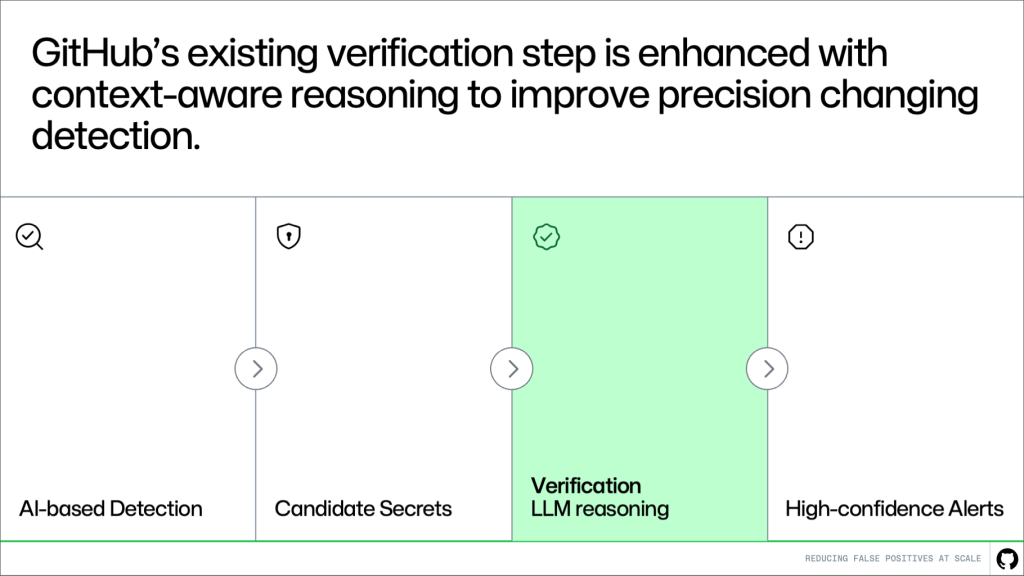
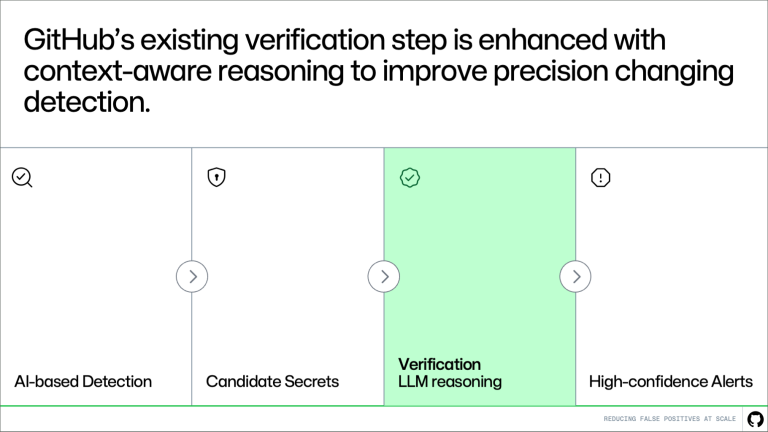
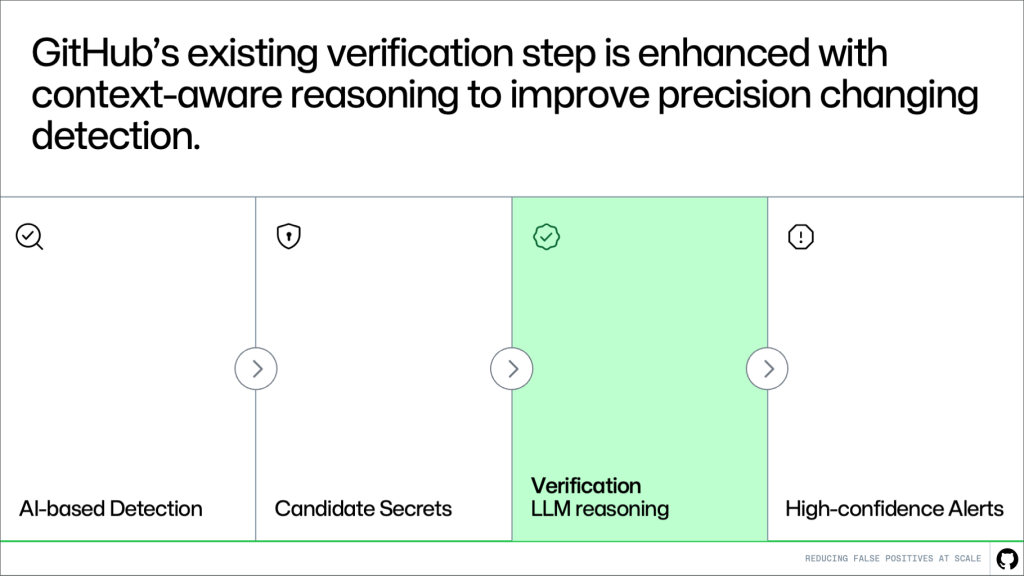
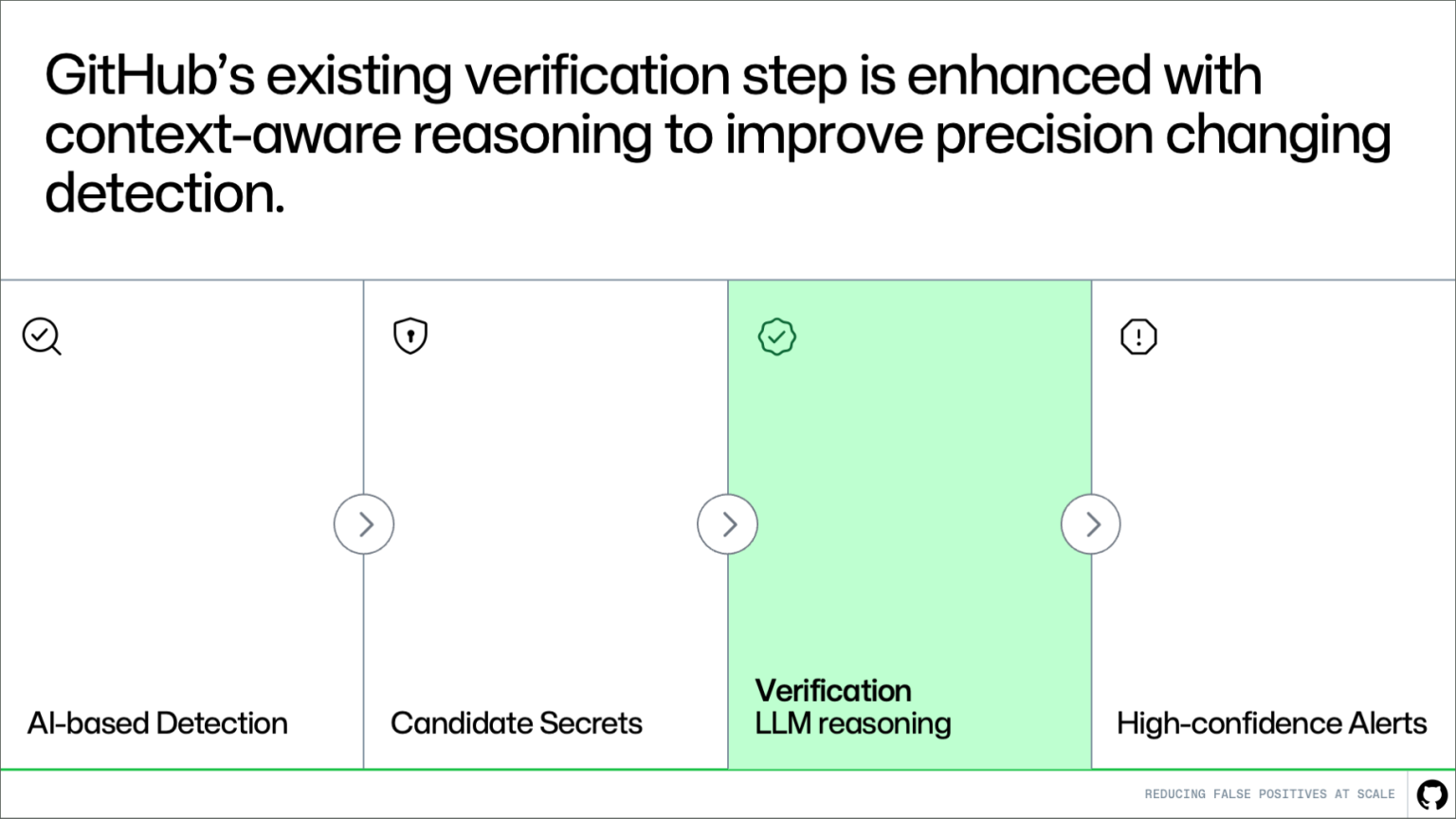
 Candidate Secrets > Verification LLM reasoning > High-confidence alerts." class="wp-image-96622" srcset="https://github.blog/wp-content/uploads/ ... png?w=1820 1820w, https://github.blog/wp-content/uploads/ ... .png?w=300 300w, https://github.blog/wp-content/uploads/ ... .png?w=768 768w, https://github.blog/wp-content/uploads/ ... png?w=1024 1024w, https://github.blog/wp-content/uploads/ ... png?w=1536 1536w" sizes="(max-width: 1000px) 100vw, 1000px" /> Where this fits in the pipeline This approach builds directly on the existing system. Detection continues to generate candidates, and the verification step evaluates them. More context-awareness makes this system better at distinguishing real secrets from noise. The result is higher precision without changing upstream detection logic or reducing coverage. How it works A key challenge in verification is deciding what context to provide. A small snippet of code is often not enough to determine whether something is a real secret. At the same time, passing entire files or repositories introduces too much noise and increases cost and latency. Instead of giving more context, we’re giving better context. Rather than send large amounts of code, we extract a small set of high-signal information that helps explain how the value is used. For example, we look for cases where a value is assigned to a variable and later passed into an API request, authentication header, database client, or cloud SDK call. Pattern matching can tell us that a value looks like a secret, but it can’t tell us whether the value is actually being used as one. The surrounding usage context helps the model distinguish real exposures from false alarms, such as random UUIDs or opaque strings, without reviewing the full file or repository.
Candidate Secrets > Verification LLM reasoning > High-confidence alerts." class="wp-image-96622" srcset="https://github.blog/wp-content/uploads/ ... png?w=1820 1820w, https://github.blog/wp-content/uploads/ ... .png?w=300 300w, https://github.blog/wp-content/uploads/ ... .png?w=768 768w, https://github.blog/wp-content/uploads/ ... png?w=1024 1024w, https://github.blog/wp-content/uploads/ ... png?w=1536 1536w" sizes="(max-width: 1000px) 100vw, 1000px" /> Where this fits in the pipeline This approach builds directly on the existing system. Detection continues to generate candidates, and the verification step evaluates them. More context-awareness makes this system better at distinguishing real secrets from noise. The result is higher precision without changing upstream detection logic or reducing coverage. How it works A key challenge in verification is deciding what context to provide. A small snippet of code is often not enough to determine whether something is a real secret. At the same time, passing entire files or repositories introduces too much noise and increases cost and latency. Instead of giving more context, we’re giving better context. Rather than send large amounts of code, we extract a small set of high-signal information that helps explain how the value is used. For example, we look for cases where a value is assigned to a variable and later passed into an API request, authentication header, database client, or cloud SDK call. Pattern matching can tell us that a value looks like a secret, but it can’t tell us whether the value is actually being used as one. The surrounding usage context helps the model distinguish real exposures from false alarms, such as random UUIDs or opaque strings, without reviewing the full file or repository. 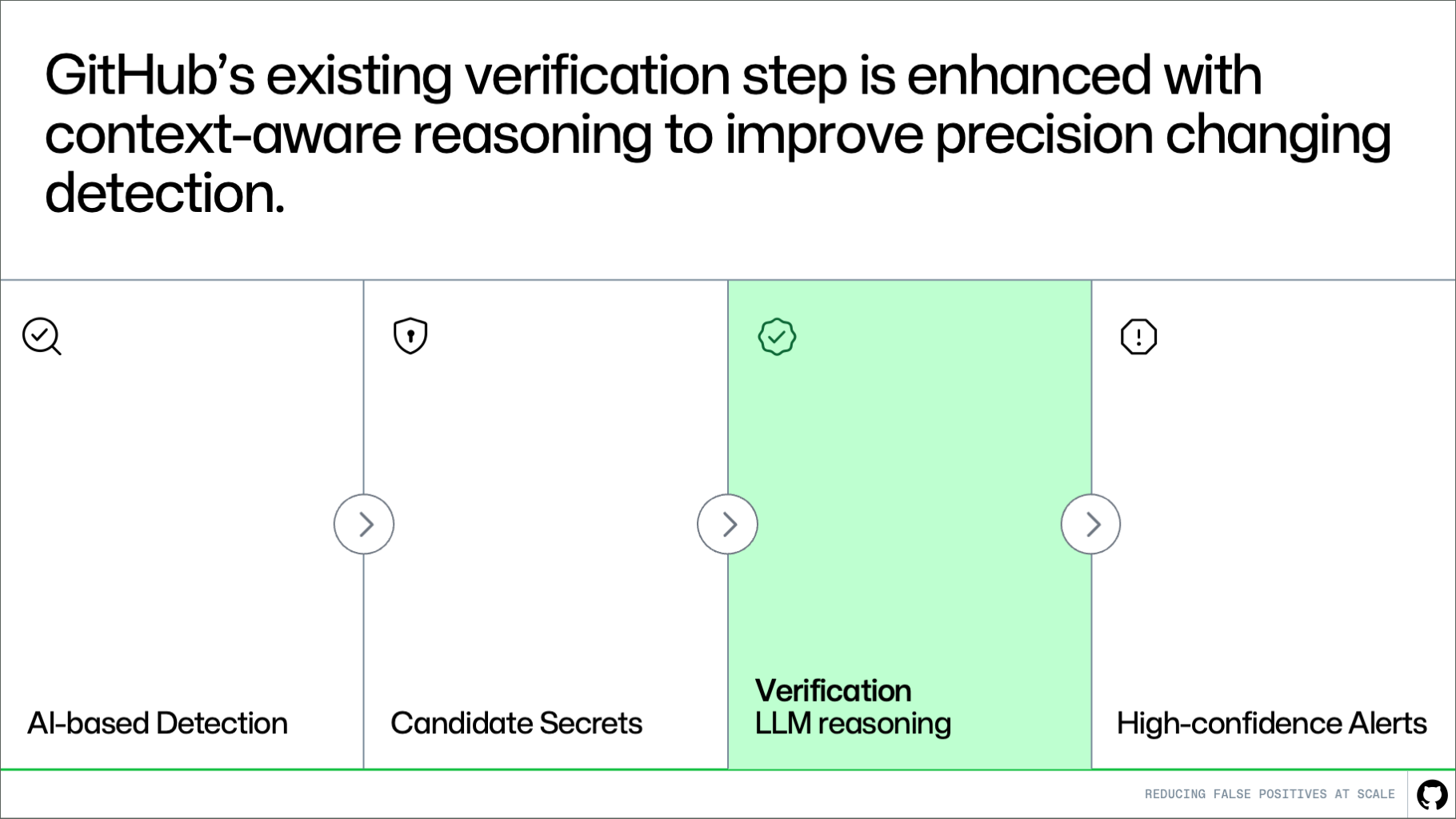{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
 Focused context, not more data It’s natural to assume that improving accuracy requires analyzing more of the codebase. But the opposite is true. Most false positives can be resolved with focused, file-level context. What matters is not how much code the model sees, but whether it has the right signals. In many cases, you can determine whether a value is a real secret by looking at how it is used within a single file. Values that resemble placeholders, test data, or unused configuration can often be filtered out without deeper analysis. This keeps the system both effective and practical: high accuracy, low latency, and the ability to scale across large codebases. Results: reducing false positives in practice We evaluated this approach on hundreds of customer-confirmed false positive alerts. Our target was a 65% reduction. The result was 75.76%, exceeding that goal while maintaining strong detection performance. In practice, this means significantly less noise and a higher proportion of alerts that require action.
Focused context, not more data It’s natural to assume that improving accuracy requires analyzing more of the codebase. But the opposite is true. Most false positives can be resolved with focused, file-level context. What matters is not how much code the model sees, but whether it has the right signals. In many cases, you can determine whether a value is a real secret by looking at how it is used within a single file. Values that resemble placeholders, test data, or unused configuration can often be filtered out without deeper analysis. This keeps the system both effective and practical: high accuracy, low latency, and the ability to scale across large codebases. Results: reducing false positives in practice We evaluated this approach on hundreds of customer-confirmed false positive alerts. Our target was a 65% reduction. The result was 75.76%, exceeding that goal while maintaining strong detection performance. In practice, this means significantly less noise and a higher proportion of alerts that require action. 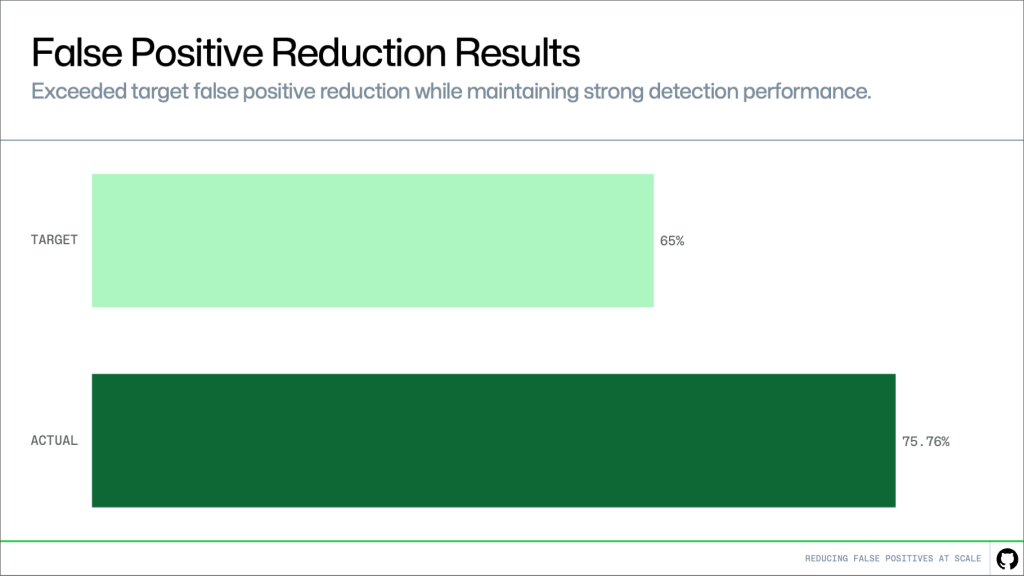 False positive reduction results based on hundreds of customer-confirmed false positive alerts. This improvement shows up directly in the developer experience. With fewer irrelevant alerts, it becomes easier to trust what you see. Less time is spent triaging noise, and real issues can be prioritized and fixed faster. What’s next We’re continuing to evaluate this approach on larger datasets and live traffic, while improving how context is extracted and used for verification. Reducing false positives has been a consistent need at scale. This work focuses on improving signal quality where it matters most, making alerts easier to trust and act on. The goal is simple: fewer distractions, clearer signals, and faster action on real risks. Get started by running the risk assessment for your organization today, or learn more about secret scanning. The post Making secret scanning more trustworthy: Reducing false positives at scale appeared first on The GitHub Blog.
False positive reduction results based on hundreds of customer-confirmed false positive alerts. This improvement shows up directly in the developer experience. With fewer irrelevant alerts, it becomes easier to trust what you see. Less time is spent triaging noise, and real issues can be prioritized and fixed faster. What’s next We’re continuing to evaluate this approach on larger datasets and live traffic, while improving how context is extracted and used for verification. Reducing false positives has been a consistent need at scale. This work focuses on improving signal quality where it matters most, making alerts easier to trust and act on. The goal is simple: fewer distractions, clearer signals, and faster action on real risks. Get started by running the risk assessment for your organization today, or learn more about secret scanning. The post Making secret scanning more trustworthy: Reducing false positives at scale appeared first on The GitHub Blog. Source: https://github.blog/security/making-sec ... -at-scale/